JoyAI-Echo深度解析:京东开源的5分钟长视频生成AI,突破音视频生成新边界(2026)

2026年6月,京东开源的JoyAI-Echo项目在GitHub上迅速获得716颗星。这个Python项目代表了长视频生成技术的重大突破——能够生成长达5分钟、包含音频的多镜头视频,且保持角色外观和声音的一致性。本文深度解析JoyAI-Echo的技术原理、应用场景和未来展望。
目录
什么是JoyAI-Echo
产品定位
JoyAI-Echo是京东AI研究院开发的长视频生成模型,能够从文本描述生成长达5分钟的高质量视频,包含:
- 多镜头切换:自动场景转换
- 音频同步:语音、音乐、音效
- 角色一致性:外观和声音保持一致
- 高分辨率:支持1080p输出
技术突破
传统视频生成的限制:
- 生成时长:通常<30秒
- 音频分离:视频和音频分开生成
- 角色漂移:长视频中角色外观变化
- 场景单一:缺乏多镜头切换
JoyAI-Echo的突破:
- 生成时长:5分钟+
- 音频同步:音视频一体化生成
- 角色一致性:外观+声音双保持
- 多镜头:自动场景切换
核心技术架构
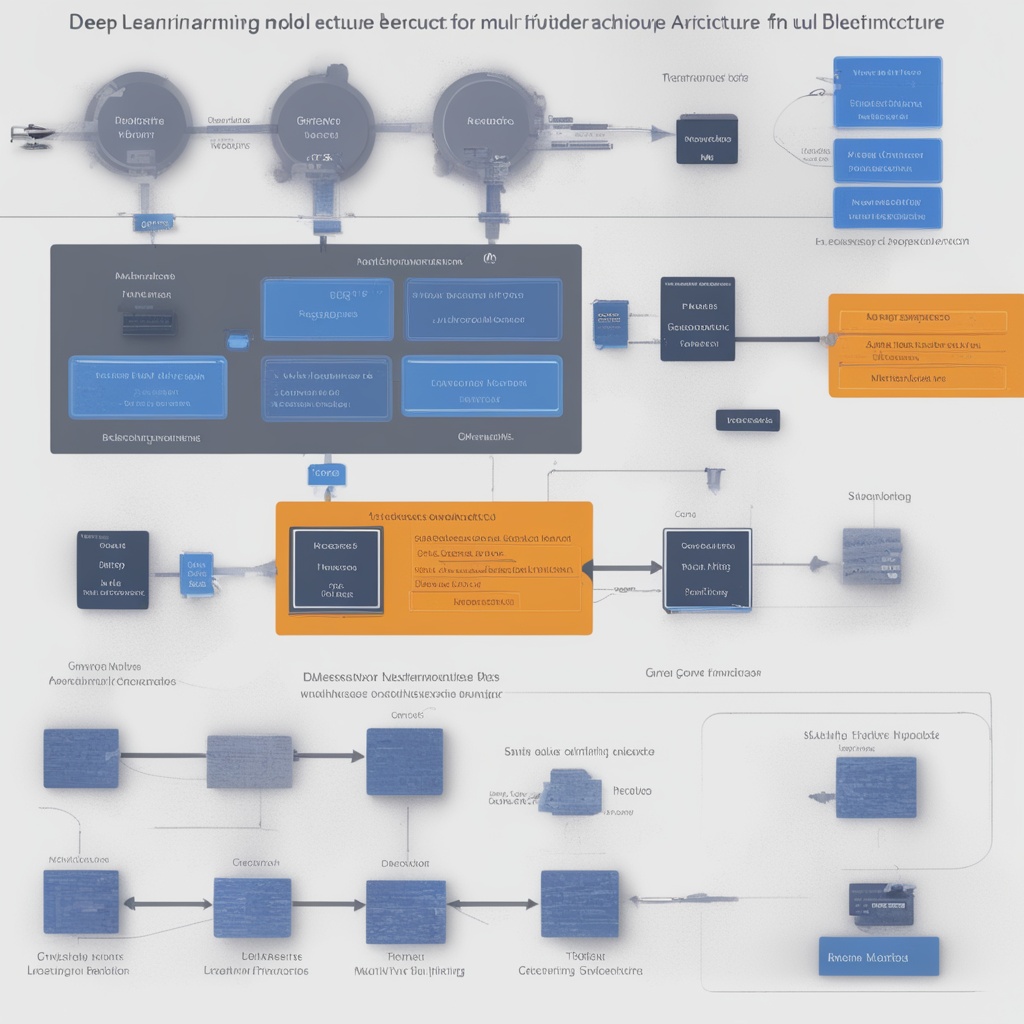
整体架构
文本输入
↓
┌─────────────────────────────────┐
│ 故事板生成器 │
│ (Story Board Generator) │
│ 文本 → 场景描述 → 镜头规划 │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 视频生成器 │
│ (Video Generator) │
│ 场景描述 → 视频帧序列 │
│ ├── 角色一致性模块 │
│ ├── 场景转换模块 │
│ └── 运动控制模块 │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 音频生成器 │
│ (Audio Generator) │
│ 视频内容 → 音频序列 │
│ ├── 语音生成模块 │
│ ├── 音乐生成模块 │
│ └── 音效生成模块 │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 音视频同步器 │
│ (Audio-Video Synchronizer) │
│ 视频帧 + 音频 → 最终视频 │
└─────────────────────────────────┘
↓
最终输出视频 (5分钟, 1080p)
关键技术模块
1. 故事板生成器
将文本描述转换为结构化的故事板:
story_board = {
"scenes": [
{
"description": "一个年轻人在咖啡店工作",
"duration": 30, # 秒
"camera": "中景",
"mood": "专注"
},
{
"description": "他收到一封重要邮件",
"duration": 15,
"camera": "特写",
"mood": "惊讶"
}
]
}
2. 角色一致性模块
使用**角色嵌入(Character Embedding)**技术,确保角色在不同镜头中保持一致:
class CharacterConsistency:
def __init__(self):
self.character_encoder = CLIPTextEncoder()
self.face_encoder = ArcFace()
self.voice_encoder = SpeakerEncoder()
def encode_character(self, description, reference_image, reference_audio):
# 多模态角色编码
text_emb = self.character_encoder(description)
face_emb = self.face_encoder(reference_image)
voice_emb = self.voice_encoder(reference_audio)
return concat([text_emb, face_emb, voice_emb])
3. 音频同步模块
使用**音视频对齐(Audio-Video Alignment)**技术:
class AudioVideoSync:
def sync(self, video_frames, audio_segments):
# 唇形同步
lip_synced = self.lip_sync(video_frames, audio_segments)
# 音乐节奏匹配
rhythm_aligned = self.align_rhythm(lip_synced, audio_segments)
# 音效空间化
spatial_audio = self.spatialize(rhythm_aligned, audio_segments)
return spatial_audio
与同类工具对比

横向对比
| 工具 | 时长 | 音频 | 角色一致性 | 多镜头 | 开源 |
|---|---|---|---|---|---|
| JoyAI-Echo | 5分钟 | ✅ | ✅ | ✅ | ✅ |
| Sora | 1分钟 | ❌ | 部分 | ❌ | ❌ |
| Runway Gen-3 | 10秒 | ❌ | ❌ | ❌ | ❌ |
| Pika | 4秒 | ❌ | ❌ | ❌ | ❌ |
| Kling | 2分钟 | ❌ | 部分 | ❌ | ❌ |
| CogVideoX | 6秒 | ❌ | ❌ | ❌ | ✅ |
| Open-Sora | 16秒 | ❌ | ❌ | ❌ | ✅ |
JoyAI-Echo的独特优势
- 最长生成时长:5分钟 vs 其他工具的秒级
- 音视频一体化:唯一同时生成视频和音频的开源工具
- 角色双一致性:外观+声音同时保持一致
- 多镜头切换:自动场景转换,类似电影剪辑
- 完全开源:Apache 2.0许可证
应用场景全景

1. 短视频创作
应用场景:
- 抖音/TikTok短视频
- YouTube Shorts
- Instagram Reels
优势:
- 从文字脚本直接生成视频
- 自动配音和字幕
- 多镜头自动剪辑
商业价值:
- 内容创作效率提升100倍
- 降低制作成本90%
- 支持批量生产
2. 企业宣传片
应用场景:
- 产品介绍视频
- 品牌故事视频
- 培训视频
优势:
- 从文案直接生成
- 专业级画质
- 支持定制角色
3. 教育内容
应用场景:
- 在线课程视频
- 知识科普视频
- 语言学习视频
优势:
- 多语言支持
- 角色一致性
- 自动字幕
4. 游戏与动画
应用场景:
- 游戏过场动画
- 动画短片
- 虚拟偶像内容
优势:
- 角色一致性
- 多镜头切换
- 音频同步
5. 电商内容
应用场景:
- 产品展示视频
- 直播切片
- 种草视频
优势:
- 批量生成
- 多样化场景
- 低成本
实战使用指南
环境要求
# 硬件
GPU: NVIDIA A100 80GB (推荐) / RTX 4090 24GB (最低)
RAM: 64GB+
存储: 100GB+
# 软件
Python: 3.10+
CUDA: 12.0+
PyTorch: 2.1+
安装步骤
# 1. 克隆仓库
git clone https://github.com/jd-ai/JoyAI-Echo.git
cd JoyAI-Echo
# 2. 创建环境
conda create -n joyai python=3.10
conda activate joyai
# 3. 安装依赖
pip install -r requirements.txt
# 4. 下载模型
python scripts/download_models.py
生成视频
from joyai_echo import JoyAIEcho
# 加载模型
model = JoyAIEcho.from_pretrained("jd-ai/JoyAI-Echo-v1")
# 生成视频
result = model.generate(
prompt="一个年轻人在咖啡店工作,突然收到一封重要邮件,表情从专注变为惊讶。他站起来,走出咖啡店,阳光洒在脸上。",
duration=60, # 秒
resolution="1080p",
fps=24,
include_audio=True,
character_reference="path/to/character.jpg",
voice_reference="path/to/voice.wav"
)
# 保存视频
result.save("output/video.mp4")
批量生成
prompts = [
"产品展示:手机从包装盒中取出,屏幕亮起",
"教程:如何安装Python,步骤演示",
"故事:小猫在花园里追逐蝴蝶"
]
for i, prompt in enumerate(prompts):
result = model.generate(prompt=prompt, duration=30)
result.save(f"output/video_{i}.mp4")
技术局限与挑战
当前局限
1. 计算资源需求高
- A100 80GB才能流畅运行
- 5分钟视频生成需要30-60分钟
- 批量生成成本较高
2. 角色一致性仍有挑战
- 极端角度下可能出现漂移
- 复杂场景中可能混淆
- 需要高质量参考图
3. 音频质量有待提升
- 语音自然度不如专业配音
- 音乐生成质量一般
- 音效匹配度有限
4. 长视频连贯性
- 5分钟视频可能出现逻辑断裂
- 场景转换可能不自然
- 需要人工后期调整
解决方案
| 挑战 | 解决方案 |
|---|---|
| 计算资源 | 使用云GPU、模型量化 |
| 角色一致性 | 提供多角度参考图 |
| 音频质量 | 后期配音、音乐替换 |
| 连贯性 | 分段生成、人工剪辑 |
未来展望

技术发展方向
1. 更长视频
- 从5分钟到30分钟
- 支持完整短片生成
- 剧情连贯性提升
2. 更高质量
- 4K分辨率支持
- 更逼真的物理模拟
- 更自然的面部表情
3. 交互式生成
- 实时调整生成内容
- 支持用户反馈
- 迭代式优化
4. 多模态融合
- 视频+3D场景
- 视频+虚拟现实
- 视频+增强现实
商业化路径
总结
JoyAI-Echo代表了视频生成技术的最新突破——从秒级到分钟级,从纯视频到音视频一体化,从单镜头到多镜头。它的开源性质和出色的性能,让长视频内容创作变得前所未有地简单。
关键要点:
- ✅ 5分钟长视频生成(业界最长)
- ✅ 音视频一体化生成
- ✅ 角色外观+声音双一致性
- ✅ 多镜头自动切换
- ✅ 完全开源(Apache 2.0)
- ✅ 应用场景广泛
适用人群:
- 内容创作者(短视频、YouTube)
- 企业市场部(宣传片、培训)
- 教育机构(在线课程)
- 游戏开发者(过场动画)
- 电商卖家(产品视频)
本文基于京东AI研究院的开源项目撰写。项目地址:github.com/jd-ai/JoyAI-Echo
评论